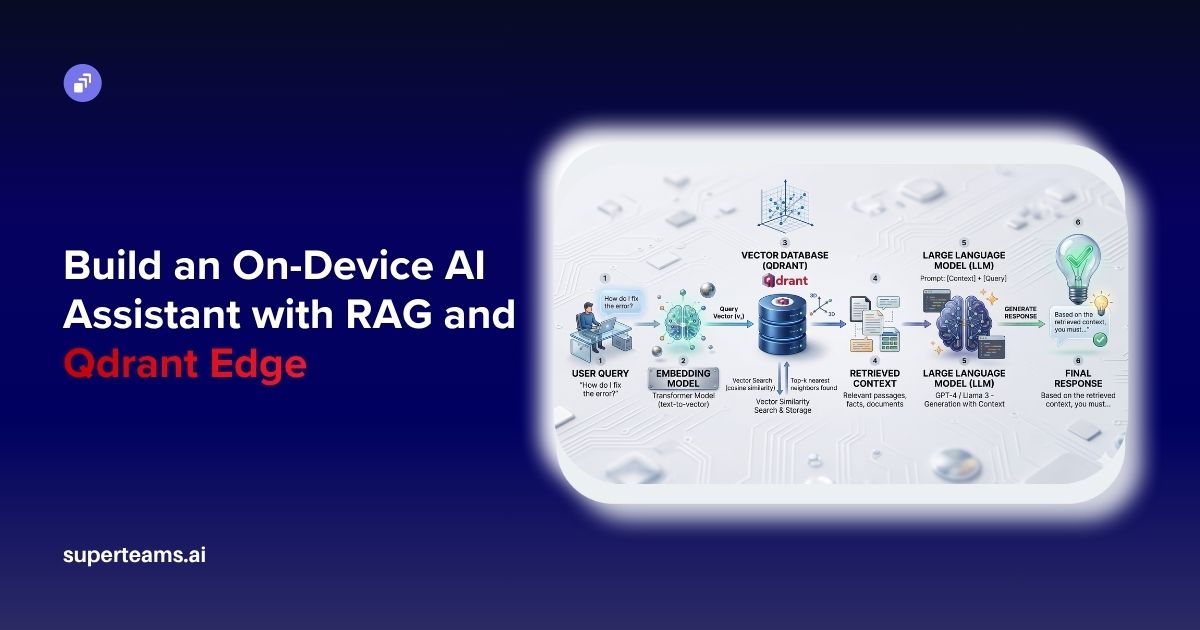
How to Use Llama-3.2-11B Vision Instruct Model to Convert Unstructured Data Into Structured Formats
Learn how to use Llama3.2-11B-Vision-Instruct model to convert PDFs into structured output, and use it for parsing charts, reports, invoices and other documents.

Accurate accounting and reporting is a key challenge that every business faces. However, one of the biggest hindrances to getting it right is the growing mountain of unstructured data. In fact, much of the world’s data is unstructured (nearly 80%) — all scattered across scanned PDFs, handwritten notes, and various formats that aren’t easily usable for analysis or reporting. Converting this data into a structured format manually is time-consuming, prone to errors, and resource-intensive. Can emerging large vision models solve this?
In this article, we will walk you through the steps to use the Llama-3.2-11B-Vision-Instruct model to parse text from images in a structured format. We will demonstrate how the model performs on a range of such tasks, including prescription parsing, invoice parsing, or even making sense of transport or fuel data.
Let’s take an example of why this is useful. The recent expansion of 10-K reporting requirements by the SEC, as announced on March 6th 2024, places significant pressure on companies to provide more detailed and accurate emissions data. For ESG-focused businesses, these regulations mean that simply having raw data is no longer enough — you need to ensure that your emissions information is structured and transparent, ready for submission in formats that align with stringent compliance standards. As the expectations for disclosures increase, manual data management can quickly become a bottleneck. This is where AI can help, and we will show you how.
Note - If you are simply looking for a solution, without diving into the technical details, you can reach out to us for a demo of our NextNeural engine. With NextNeural engine, we are building a growing repository of agentic AI modules that solve business problems like the above.
Ok, let’s get started.
Understanding the Landscape of Large Vision Models
Before we dive in, it will help to understand what large vision models are, and why they trump traditional optical character recognition (OCR) systems. Unlike traditional OCR systems that are primarily designed to extract text from images using naive algorithms, large vision models, like GPT4o or Pixtral-12B or Llama 3.2-11B-Vision-Instruct, are capable of far more.
These models are multimodal, meaning they can process both text and images, and are built using advanced deep learning algorithms that understand context, recognize patterns, and extract structured data from complex unstructured inputs. Where traditional OCR may struggle with poor-quality scans, handwriting, or mixed formats, large vision models can intelligently interpret visual information in a way that mimics human understanding.
Several vision language models have emerged in the last few months. However, the choice of the right model depends on your requirements. For instance, if your data is such that you don’t need to worry when you share it with GPT models like 4o, then we recommend going that route to save cost. On the other hand, if you have stringent data compliance requirements, you would be better served if you host a model like Llama 3.2-11B-Vision or Pixtral-12B on your own infrastructure, where you don’t end up sharing your internal data with platform companies.
Here’s a comparison table for simplicity:
The table above illustrates the key differentiators between these large vision models, each suited for different levels of complexity, privacy needs, and cost considerations. For companies dealing with sensitive emissions data and stringent ESG reporting requirements, models like Llama 3.2-11B-Vision-Instruct or Pixtral-12B offer significant advantages, particularly because they can be hosted on your own infrastructure, ensuring that your data remains secure and private. They also allow for a high degree of customization, meaning you can fine-tune these models to better interpret the specific kinds of unstructured emissions data your company handles.
Ok, now let’s look at the steps to use these models for parsing unstructured data into structured formats.

Steps to Use Llama-3.2-11B-Vision-Instruct
To begin with, you will first need to get access to the model - Llama-3.2-11B-Vision-Instruct. To do so, head over to Hugging Face, create an account, and register your intent to access the model. You will need to fill up some basic information, based on which the model maintainers from Meta will grant you access.
You will also need a high-end cloud GPU. We have used the NVIDIA Tensor Core A100 GPU for this tutorial. Once you have launched the GPU and a corresponding Jupyter notebook, you can check your GPU configuration:
!nvidia-smiThis command will show you the GPU configuration and memory usage. You will also need to create an access token on Hugging Face, so you can download the model. Once you create the access token, save it in an environment variable.
So, in your .env file, add this line:
HF_TOKEN='your_access_token_from_hugging_face'We will now install the required libraries.
pip install torch requests Pillow accelerate python-dotenv
pip install git+https://github.com/huggingface/transformersNext, let’s import the required libraries:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from dotenv import load_dotenv
load_dotenv()
Now we are set.
Step 1: Download the Model
If you have saved the access token in your .env file, you won’t need to use huggingface_hub to login. You can now download the model.
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)This will take some time, as the model is fairly large. Brew some coffee!
Step 2: Test the Model
Once the model has downloaded, you can test it by giving simple instructions using an image. Here’s how:
image = Image.open("emissions_per_person.png")
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": """
Capture the emission per person by country in a table format with numbers.
Provide approximate floating point numbers.
"""}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=1000)
response = processor.decode(output[0])
print(response)To test, we have used the following image, which shows the carbon dioxide emissions per person from 15 countries with the largest total emissions.

This is the output we get:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
<|image|>
Capture the emission per person by country in a table format with numbers.
Provide approximate floating point numbers.
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The following table presents the carbon dioxide emissions per person, measured in tons of CO2e, for 15 countries with the highest total emissions. The data is displayed in a table format with approximate floating-point numbers.
| Country | Emissions per Person (tCO2e) |
| :--------------- | :--------------------------: |
| Saudi Arabia | 18.4 |
| USA | 16.5 |
| Canada | 14.4 |
| S. Korea | 12.1 |
| Russia | 10.4 |
| Japan | 8.6 |
| China | 7.2 |
| Germany | 6.9 |
| Iran | 5.4 |
| S. Africa | 4.5 |
| Turkey | 4.2 |
| Mexico | 3.8 |
| Indonesia | 3.4 |
| Brazil | 3.3 |
| India | 1.7 |
**Answer:** The table provides a concise overview of the carbon dioxide emissions per person for 15 countries with the highest total emissions.<|eot_id|>As you can see, the numbers are more or less within range.
Step 3: Using the Model for Structured Outputs
One of the factors we have noticed is that the model is better with generating output in markdown format, rather than JSON or YAML. So, our approach will be to first steer it to generate markdown, and then convert the markdown to JSON.
Take a look at the image file we will be using:

This is a fairly complicated bill, and your accounting team probably gets thousands of these. Let’s test the AI model on this bill. Our prompt will steer the markdown this time:
image = Image.open("water_bill.png")
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": """
Parse the bill image in markdown format. Capture all details, and fill up these values:
Account Number:
Account Name:
Address:
Bill from:
Bill to:
Bill due date:
Bill total:
Due date:
Amount after due date:
"""}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=1000)
response = processor.decode(output[0])
print(response)This will generate a response like this:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
<|image|>
Parse the bill image in markdown format. Capture all details, and fill up these values:
Account Number:
Account Name:
Address:
Bill from:
Bill to:
Bill due date:
Bill total:
Due date:
Amount after due date:
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
**Water Bill Details**
* **Account Information**
+ Account Number: 0441-12-022
+ Account Name: Balingit Joe
+ Address: Rizal
* **Billing Period**
+ Bill From: 10/03/2022
+ Bill To: 11/02/2022
* **Bill Due Date**: 11/17/2022
* **Bill Total**: 210.00
* **Due Date**: 11/17/2022
* **Amount After Due Date**: 220.50<|eot_id|>As you can see, the data captured is more or less accurate. However, the model does hallucinate sometimes, so manual oversight is necessary.
Step 4: Generating Structured Output
With the GPT 4o model, you can easily generate the output in a JSON, Zod, or Pydantic structure. However, that is not the case with the open-source vision models currently.
In order to generate structured output markdown, you would need to convert the markdown into JSON format. First, we will strip out the Llama-3.2 specific tags and extraneous data:
def parse_eot_content(input_string):
# Step 1: Find the content between the <|eot_id|> tags
eot_pattern = r"<\|eot_id\|>(.*?)<\|eot_id\|>"
eot_match = re.search(eot_pattern, input_string, re.DOTALL)
if eot_match:
eot_content = eot_match.group(1)
else:
return None # If no content between <|eot_id|> tags
# Step 2: Remove the section within <|start_header_id|> and <|end_header_id|>
header_pattern = r"<\|start_header_id\|>.*?<\|end_header_id\|>"
cleaned_content = re.sub(header_pattern, '', eot_content, flags=re.DOTALL)
# Step 3: Return the cleaned content
return cleaned_content.strip()
We will also write a simple function to parse the markdown data into JSON format, like this:
def markdown_to_json(markdown):
data = {}
current_section = None
# Split by line
lines = markdown.splitlines()
for line in lines:
line = line.strip()
# If the line is empty, skip it
if not line:
continue
# If the line is a new section title (bolded text)
section_match = re.match(r'\*\*(.+?)\*\*', line)
if section_match:
current_section = section_match.group(1).strip()
data[current_section] = {}
continue
# If the line starts with "*", handle it as a list item or key-value pair
if line.startswith("*"):
# Remove the asterisk and any surrounding whitespace
line = line.lstrip("*").strip()
key_value_match = re.split(r':\s+', line, maxsplit=1)
# Handle key-value pairs at the root level
if len(key_value_match) == 2:
key, value = key_value_match
data[current_section][key] = value
continue
# If the line starts with "+", it's a key-value pair inside a section
if line.startswith("+"):
line = line.lstrip("+").strip()
key_value_match = re.split(r':\s+', line, maxsplit=1)
# Add the key-value pair to the current section
if len(key_value_match) == 2:
key, value = key_value_match
if current_section:
data[current_section][key] = value
else:
data[key] = value
return json.dumps(data, indent=4)
We can now convert the Llama-3.2 output using these functions.
parsed_output = parse_eot_content(response)
output = markdown_to_json.jsonify(parsed_output)
print(output)This will generate the following result:
{
"Water Bill Details": {
"Account Number": "0441-12-022",
"Account Name": "Balingit Joe",
"Address": "Rizal",
"From": "10/03/2022",
"To": "11/02/2022",
"Billing Due Date": "11/17/2022",
"Current Bill Amount": "210.00",
"Total Amount Due": "210.00",
"Due Date": "11/22/2022"
}
}
You can now insert this into a database, and query away.
How Does NextNeural Help with Massive Scale Parsing?
NextNeural is a set of modules and agentic workflows that simplify language and vision challenges in enterprises. With the NextNeural engine, you can bulk process thousands of unstructured documents to generate structured outputs that can later be normalized according to your database schema or integrated into your workflows.
In addition to the above, NextNeural also has the capability to validate the output of one model against another. This is a simple yet powerful tactic to ensure accuracy of structured data.
To learn more, schedule a consultation with our team.
Summary
The Llama-3.2-11B Vision Instruct model presents a powerful solution to the challenge of converting unstructured data into structured formats. With its advanced multimodal capabilities, it can parse complex visual inputs like scanned invoices, prescriptions, and even emissions data, offering companies a reliable way to manage their reporting needs efficiently.
For industries such as ESG-focused businesses that deal with stringent regulatory compliance, this model’s ability to maintain privacy and deliver accurate, structured data is invaluable. While some manual oversight is still required, the benefits of automating these processes far outweigh the limitations.
If your business is facing challenges with managing unstructured data or with compliance reporting, now is the perfect time to explore AI-driven solutions. Schedule a demo of our NextNeural engine and see first-hand how we can help you streamline your document processing and data management tasks at scale.
Authors
Want to Scale Your Business with AI Deployed on your Cloud?