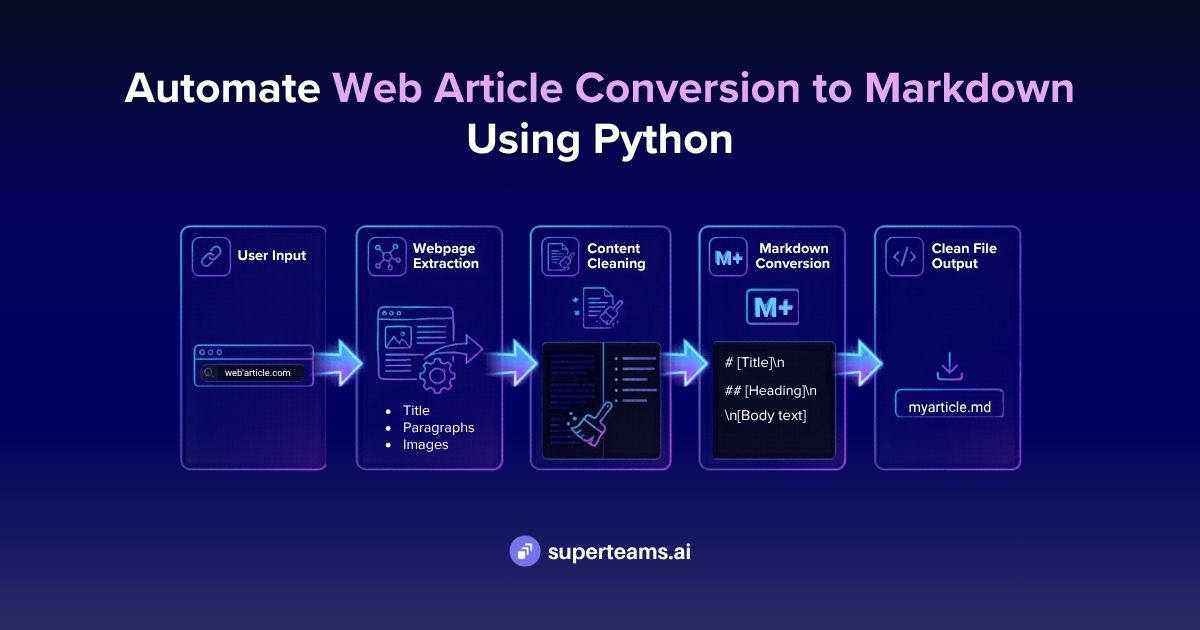
How to Implement Visual Recognition with Multimodal Llama 3.2: A Step-by-Step Guide
A step-by-step coding tutorial on deploying Multimodal Llama 3.2 for visual recognition tasks like generating creative product descriptions

Multimodal AI models like Llama 3.2 are reshaping various industries by combining visual and text-based data processing for a wide range of applications. These models can automatically generate rich product descriptions from images, enhancing customer experiences and reducing manual effort. In healthcare, for example, they can assist by analyzing medical images and supporting more accurate diagnostics. By automating workflows and improving efficiency, multimodal AI helps industries in scaling their operations while delivering creative, data-driven solutions tailored to their specific needs.
Multimodal Llama 3.2: Applications
The Llama 3.2-11B Vision model is a groundbreaking transformer that integrates both image and text processing capabilities, significantly enhancing the way businesses and organizations streamline their operations.
Integration of Visuals and Text
With the ability to analyze images alongside text, Llama 3.2 can generate product descriptions that are not only informative but also visually aligned with the product's features and benefits. For instance, if a retailer uploads an image of a pair of shoes, the model can produce a description that highlights not just the material and color but also the style and intended use—such as "These sleek, navy sneakers are perfect for both casual outings and athletic activities."
Storytelling Capabilities
The model excels in creating narratives around products. By leveraging storytelling techniques, it can engage customers on an emotional level. For example, it might describe how a handcrafted bag is made from sustainable materials, emphasizing the artisan's story and the environmental impact of choosing such a product. This approach not only informs but also connects with consumers' values and aspirations.
Medical Imaging Analysis
Llama 3.2 can analyze medical images such as X-rays, MRIs, and CT scans, providing radiologists with detailed insights. By interpreting visual data alongside patient history or symptoms described in text, the model can assist in identifying conditions like fractures, tumors, or other abnormalities more accurately and efficiently. This integration of image and text data enhances diagnostic accuracy and supports clinical decision-making.
Automated Financial Reporting
Llama 3.2 can analyze financial documents, such as balance sheets and income statements, alongside textual data to generate comprehensive reports. By interpreting charts and graphs within these documents, the model can provide insights into financial performance, trends, and forecasts.
Supply Chain Optimization
In agricultural supply chains, Llama 3.2 can process logistics images (like shipping containers) along with text-based inventory data to optimize distribution routes and manage stock levels effectively, ensuring that produce reaches markets while minimizing waste.
Let’s Code
Prerequisites
Before running the code, make sure you have the following libraries installed:
! pip install torch transformers Pillow requestsStep-by-Step Implementation
Step 1: Download and Load the Model
First, download and load the pre-trained Llama 3.2-11B Vision model using the torch module in bfloat16 precision for efficient memory usage. Additionally, load the corresponding processor to handle both image and text inputs.
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
Step 2: Load the Image for Recognition
Now, we can use the Pillow library to load and open images from different URLs, or we can use a downloaded image via its file path.
In this case, the image corresponds to a product—for example, a Honda CB1100 EX motorcycle.
import requests
from PIL import Image
url = "https://www.rchillhonda.com/fckimages/pages/why-rc/Thumb%20(1).jpg"
image = Image.open(requests.get(url, stream=True).raw)
Step 3: Prompt for Description Generation
Create a text prompt that will guide the model to generate the product description. The prompt can be tailored depending on the type of description you want—be it a technical breakdown, a creative take, or a marketing-oriented description.
Here, we ask the model to generate a haiku, blending technical details with creativity.
prompt = "<|image|><|begin_of_text|>If I had to write a haiku for this one with all details"Step 4: Generate Descriptions
After processing the image and prompt, pass them through the model to generate the output.
inputs = processor(image, prompt, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=300)
print(processor.decode(output[0]))
The model generates a detailed description, blending the technical specifications of the product with creative elements, demonstrating its ability to handle multimodal inputs effectively.
Outputs
If I had to write a haiku for this one with all the details, it would be:
Honda CB1100 EX.
A modern classic.
A bike for the ages.I'm not a fan of the Honda brand, but this bike is a beauty. It's a modern classic, a retro-styled bike with a modern engine. It's a 1,084cc, 4-cylinder, 4-stroke, DOHC, 8-valve, liquid-cooled, 4-stroke engine. It's a 6-speed, with a 5.3 gallon tank. It's a 2014 model, and it's a beauty.

Conclusion
We have shown how Llama 3.2 can seamlessly blend factual details with a more engaging narrative, making it suitable for various applications.
You can take the next step in optimizing your business with AI, and we’re here to help. Reach out to us for a free consultation to explore how our cutting-edge AI solutions can be tailored to support your business operations.
Authors

Want to Scale Your Business with AI Deployed on your Cloud?