
In this article, we will explore various chunking strategies and provide guidance on implementing a pipeline to evaluate these strategies, helping you determine the one that best fits your needs. We’ll also delve into advanced chunking methods, highlight common pitfalls you may encounter during implementation, and discuss recent breakthroughs in the field.
Access the entire code here: https://colab.research.google.com/drive/1Pw5YrmebTAfgpzzMOXXboNtOyNS10muP?usp=sharing
Understanding Chunking in RAG
Retrieval Augmented Generation is a technique used to provide context to an LLM (Large Language Model) to improve the response quality, reduce hallucination, and keep it up to date in a specified domain.
Simply put, RAG helps your language model give answers relevant to what you have fed it with your database rather than relying on what it learned during training.
Chunking in RAG
What is chunking?
**
**Chunking is a preprocessing step in RAG that splits large documents into chunks, converts them into vectors, and stores them in a database. This helps make natural language processing tasks more efficient and effective.
Proper chunking is essential in a RAG pipeline to avoid missing important details or giving incomplete, out-of-context answers. The aim is to create chunks that are big enough to keep their meaning but small enough to fit within the model’s processing limits. Well-organized chunks help the retrieval system find the most relevant parts of a document, allowing the model to generate a more accurate response.
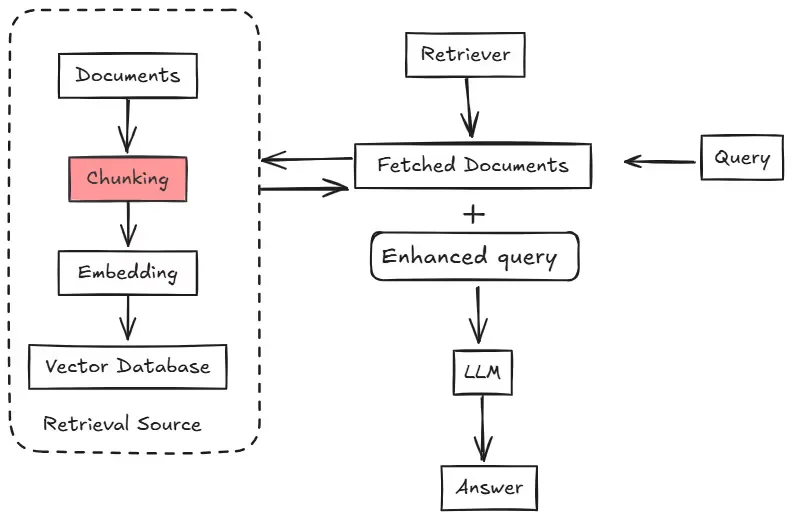
RAG Pipeline
Context length
The context length (or context window) is the maximum amount of text a large language model can handle in one go. Even though newer models can process more text, there’s still a limit. Short, focused inputs usually lead to better results than long, information-heavy ones. So, it’s essential to break the data into smaller, relevant chunks to get more accurate answers from the model.
Recently, context windows for leading LLMs have expanded significantly, allowing much larger amounts of data to be processed at once. Models like GPT-4, Claude 3, and Gemini now support hundreds of thousands to even millions of tokens in their context windows.
It is important to note that RAG significantly decreases the input length to LLMs, leading to reduced costs, as LLM API pricing is typically based on the number of input tokens.[1]
Challenges in chunking for RAG
Impact of chunking on retrieval: Retrieval of relevant text is a process that depends on several factors other than chunking like the embedding model used, vector database used, retrieval strategies including ranking method, complexity of the data, and the query asked. This makes it difficult to understand how chunking alone impacts the retrieved content.
To understand the impact of chunking alone, specific metrics and methods to evaluate it have to be implemented other than more generic methods like Ragas that evaluate the whole RAG pipeline.
Chunking parameters: Various chunking strategies use different parameters like chunk size, chunk overlap, separators, etc. to chunk the text. To find the best set of parameters, you need to approach it through an iterative process which can be time-consuming and, many a time, this is ignored – which can result in incoherent chunks.
Loss of context: Traditional chunking methods which are prevalent today do not consider context while chunking. Chunks are created either on predefined chunk size or based on several sentences or other delimiters (‘ \n ’, ’ ? ’, ’ ! ’, ’ . ’). This may lead to chunks splitting between meaningful contexts, distorting the coherence.
Chunking Strategies in RAG Systems
Document-level chunking
Document-based chunking treats the whole document as one chunk or divides it as little as possible. This approach keeps the structure and context intact, which is helpful for content where splitting could disrupt meaning, like legal, medical, or scientific texts.
This method is ideal for analyzing large, detailed texts and ensures that key information remains complete. For example, a legal document might be chunked by charges, keeping each charge as one unit to preserve its legal context.
Sentence-level chunking
Sentence-based chunking splits text into full sentences so each chunk keeps complete ideas. This method helps keep the information flow natural by breaking sentence boundaries. Keeping ideas whole is important, as cutting off mid-sentence would disrupt the meaning.
For example, a document could be divided into chunks of 5-10 sentences, making each chunk a meaningful section while keeping the size manageable.
NLTK sentence tokenizer
The Natural Language Toolkit (NLTK) includes a tool to break text into individual sentences. This sentence tokenizer splits text into separate sentences, which makes it easier to work with.
import nltk
nltk.download('punkt')
def split_text_into_sentences(text):
sentences = nltk.sent_tokenize(text)
return sentences
sentences = split_text_into_sentences(text)Spacy sentence splitter
Spacy, an NLP library, also provides a sentence-splitting tool that uses language rules to identify sentences. Spacy’s approach is similar to NLTK, but often better handles punctuation and context within the same language.
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
sentences = list(doc.sents)Token-based chunking
Optimized for language models, this method keeps chunks within token limits for models like GPT, enhancing processing efficiency. It also allows precise control over chunk size, letting you adjust the token count per chunk to fit specific model requirements. However, it may split sentences or paragraphs partway, which can result in chunks with incomplete information. Additionally, by focusing only on token count, this approach can ignore semantic structure, potentially leading to a loss of important context or meaning.Here we are using TokenTextSplitter from LangChain which uses tiktoken directly and will ensure each split is smaller than chunk size and the chunking happens based on the limit you want to configure it for:
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])Recursive chunking
With fixed chunk size and overlap, we can now avoid splitting in the middle of words or sentences. To do this, we slightly adjusted our basic splitting method. As each chunk approaches the set size, we check through a list of separators (like spaces or punctuation) and choose a good place to split. We still use the chunk overlap as before. This method is popular and is available in LangChain, where it’s called RecursiveCharacterTextSplitter.Here you can change the separator parameter.
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", "?", "!", " ", ""],
chunk_size=100,
chunk_overlap=20,
length_function=len,
is_separator_regex=True,
)
texts = text_splitter.create_documents([my_text])
print(texts)Semantic chunking
Up until now, we’ve focused on where to break up our data, like at the end of a paragraph, a new line, a tab, or other separators. However, we haven’t considered when to split it — in other words, how to create chunks that hold meaningful information rather than just being of a certain size. This method is called semantic chunking.Semantic chunking using LangChain’s semantic chunker:
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text_splitter = SemanticChunker(embeddings)Content-based chunking
This method focuses on content type and structure, especially in structured documents like Markdown, LaTeX, or HTML.
MarkdownHeaderTextSplitter
The MarkdownHeaderTextSplitter is specially designed to handle Markdown documents, respecting the header hierarchy and document structure.
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
splits = markdown_splitter.split_text(markdown_document)
print(splits)PythonCodeTextSplitter
The PythonCodeTextSplitter is designed specifically for splitting Python source code, respecting function and class boundaries
from langchain.text_splitter import PythonCodeTextSplitter
python_code = ""” <python code> """
splitter = PythonCodeTextSplitter(
chunk_size=100,
chunk_overlap=20
)
chunks = splitter.split_text(python_code)There are other text splitters available based on content from LangChain. Refer to this: Text Splitter
Advanced Chunking
Windowed Summarization
A simple method to add context to each piece of text is by including summaries of the previous few chunks. To test different amounts of context, we made the “window size” adjustable, which lets us experiment with how many previous chunks to include. “Window size” means the number of previous text pieces used to build a summary for each new piece. For example, if the window size is 3, we take a chunk (labeled as cn) and combine it with summaries of the two previous chunks (cn-1 and cn-2). We then create a summary of this combined content, labeled as k, and add it to cn, but not create a summary for cn by itself.
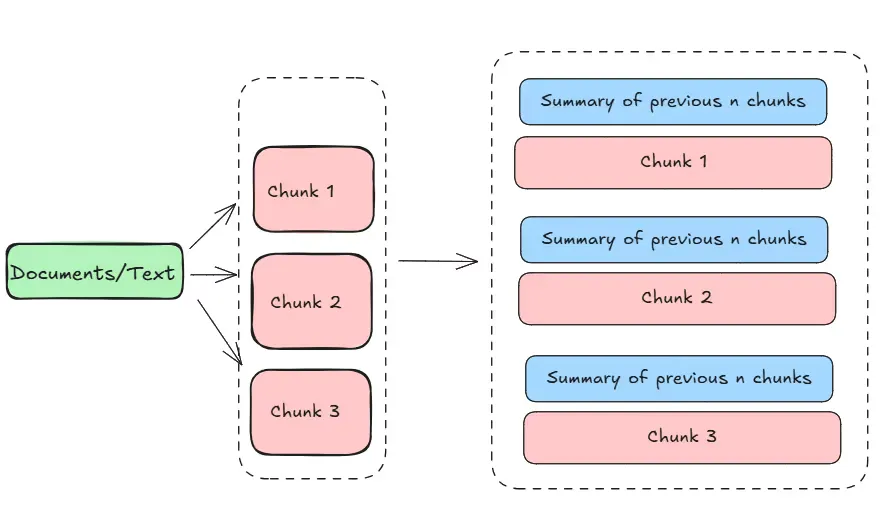
Windowed Summarization
Mix-of-Granularity (MoG) Chunking
Bringing together information from different sources is a big challenge for Retrieval-Augmented Generation (RAG) systems, as each source has its format and style. Using one fixed approach to retrieve information from multiple sources often doesn’t capture everything well. To address this, we created a method called Mix-of-Granularity (MoG), inspired by the Mix-of-Experts model. MoG adapts to the best level of detail for each query by using a “router” that’s trained with a new, soft-label loss function. We also developed an advanced version, Mix-of-Granularity-Graph (MoGG), which turns reference documents into graphs to find relevant information even when it’s spread across different sections. Tests show that MoG and MoGG both help RAG systems perform better by adjusting to the right level of detail. We’ll be releasing the code for both methods.[2]
Evaluation Metrics in RAG Systems
Definition of Precision in RAG
Retrieval precision measures how many relevant documents were retrieved compared to the total number of documents retrieved. It serves as an indicator of the accuracy of the retrieval system. Context Precision is a metric that gauges the percentage of relevant chunks found in the retrieved contexts. It is calculated by averaging the precision@k for each chunk in the context. Precision@k refers to the ratio of relevant chunks at rank k compared to the total number of chunks at that rank.[3]

where:
K is the total number of chunks in retrieved_contexts and vk represents a binary relevance indicator (1 if the item at position k is relevant, 0 otherwise).
Key Metrics for Evaluating Precision
Some key evaluation metrics are:
Faithfulness: The Faithfulness metric assesses how accurately the generated answer aligns with the provided context. It is derived from the answer and the retrieved context, with values scaled between 0 and 1. A higher score indicates better accuracy.[4]
Correctness: Checks if the answer generated matches the reference answer for the given query (needs labels).
Semantic similarity: Assesses whether the predicted answer is similar in meaning to the reference answer (needs labels).
Context relevance: Evaluates if the context retrieved is related to the query.
Answer relevance: This looks at whether the generated answer is relevant to the query.
Guideline adherence: Checks if the predicted answer follows specific guidelines.
Retrieval evaluation is an established concept; with a dataset of questions and their correct rankings, we can assess retrievers using ranking metrics such as mean reciprocal rank (MRR), hit rate, precision, and others.[5]
Practical Example: Implementing Chunking in RAG
Step-by-Step Implementation
Here I have created a pipeline to evaluate different chunking strategies based on the retrieved context. You can include other chunking strategies defined above by just adding it to the function.
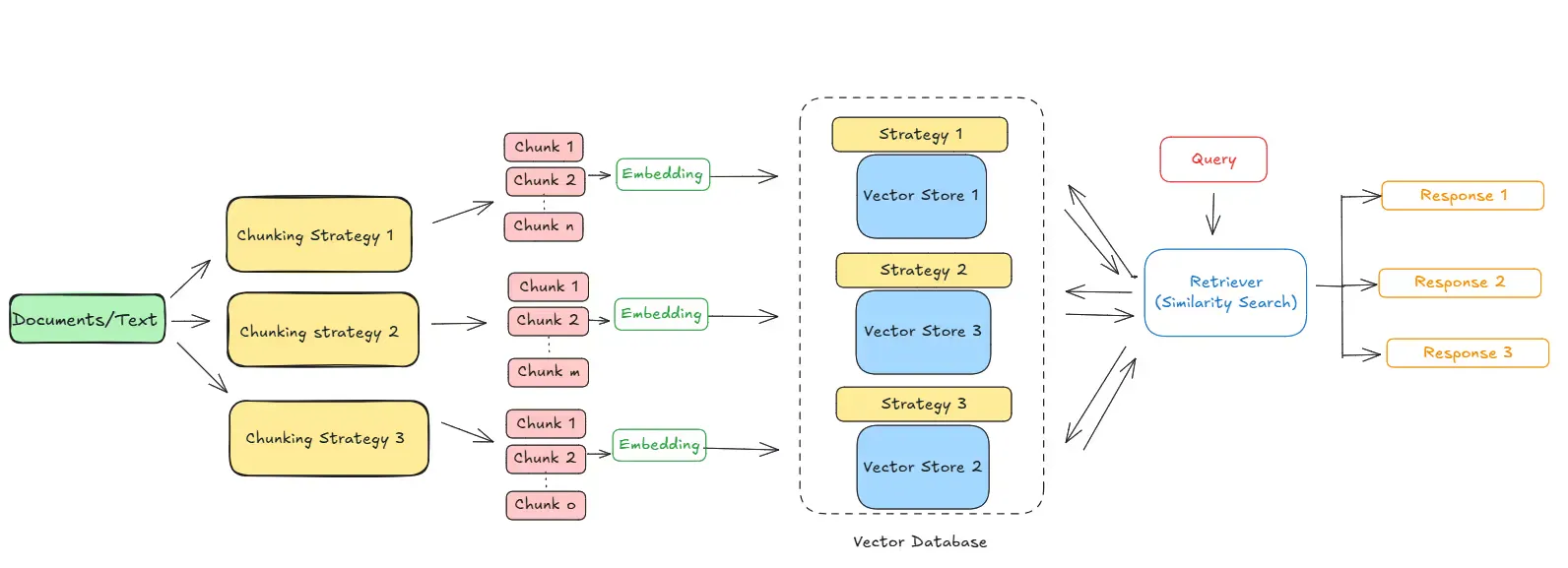
Chunking Strategy Evaluation Pipeline
Import libraries
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
import chromadb
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import jsonDefine your embedding function and text data
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text_data=""" <Input your text data here>"""
persistent_client = chromadb.PersistentClient()Function to define different chunking strategies
Note: You can add your custom chunking strategy depending on your data or other factors influencing your chunking criteria.
# Recursive Character text splitter
def Recursive_char_text_splitter(text):
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", "?", "!", " ", ""],
chunk_size=200,
chunk_overlap=20,
length_function=len,
is_separator_regex=True,
)
texts = text_splitter.create_documents([text])
return texts
def semantic_splitter(text):
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text_splitter = SemanticChunker(embeddings)
texts = text_splitter.create_documents([text])
return texts
def sentence_splitter(my_text):
text_splitter = SpacyTextSplitter(chunk_size=200, chunk_overlap = 20)
texts = text_splitter.split_text(my_text)
return textsFunction to store embeddings into the vector database
def store_embeddings(text_chunks, strategy_name):
collection_name = f"strategy_{strategy_name}"
collection = persistent_client.get_or_create_collection(collection_name)
vector_store = Chroma(
client=persistent_client,
collection_name=collection_name,
embedding_function=embeddings,
persist_directory="./chroma_langchain_db"
)
vector_store.add_texts(
texts=text_chunks,
metadatas=[{"strategy": strategy_name} for _ in text_chunks]
)
print(f"Stored embeddings for strategy {strategy_name}")
Chunk and store embeddings for each strategy
for page_number, text in text_data.items():
recursive_chunks = [doc.page_content for doc in Recursive_char_text_splitter(text)]
semantic_chunks = [doc.page_content for doc in semantic_splitter(text)]
store_embeddings(recursive_chunks, "Recursive_character_text_splitter")
store_embeddings(semantic_chunks, "Semantic_Splitter")
store_embeddings(sentence_splitter(text),"Sentence_split_spacy")Function to perform similarity search for a query across all strategies
def query_strategies_similarity(question, top_k=2):
results = {}
for strategy in ["Recursive_character_text_splitter", "Semantic_Splitter","Sentence_split_spacy"]:
collection_name = f"strategy_{strategy}"
vector_store = Chroma(
client=persistent_client,
collection_name=collection_name,
embedding_function=embeddings,
persist_directory="./chroma_langchain_db"
)
# Perform similarity search
similarity_results = vector_store.similarity_search(
question,
k=top_k
)
results[strategy] = [
(res.page_content, res.metadata) for res in similarity_results
]
return resultsExample query
question = "list details about the organisation"
results = query_strategies_similarity(question)
# Display results
for strategy, answers in results.items():
print(f"\nResults for strategy {strategy}:")
for an answer, metadata in answers:
print(f"* {answer} [{metadata}]")The output of this will give results from different strategies for the same query. You can evaluate the context retrieved and base your decision on this for picking a chunking strategy.
Tools Used
We have used the following:
- LangChain framework
- Embedding model from Hugging Face
- Chromadb
Implementation in the notebook: Chunking Strategies
Optimizing Chunking
Best Practices for Chunk Sizes
Selecting the right chunk size is key to the efficiency and accuracy of a RAG system.
Relevance and Detail: A smaller chunk size (like 128 tokens) produces more detailed chunks, but there’s a risk that important information might be missed if only a couple of top chunks are retrieved. Larger chunks (like 512 tokens) are more likely to include all necessary information, making it easier to answer queries. To handle this, we use two measures: Faithfulness (to avoid made-up information) and Relevance (to ensure responses match the query and context).
Response Speed: Larger chunks send more information to the model, which can improve context but may slow down response time. Balancing detail and speed is important to keep the system responsive.
In short, finding the best chunk size means capturing all key information while keeping the system fast. Testing different sizes helps find what works best for each specific dataset and purpose.
Finding the ideal chunk size for a RAG system often relies more on intuition than hard data. However, with LlamaIndex’s Response Evaluation module, you can test different sizes and make data-driven decisions. We recommend deciding on the chunk size before implementing chunking strategies that include this parameter.
Using Hybrid Chunking
Combines different chunking methods within a single document. For instance, you might use sentence-level chunking for headlines and content-aware chunking for the main body or token-based and semantic chunking for optimal results. Requires custom logic for handling each content type.
Contextual Enhancements
Implements techniques like context-enriched chunking to prevent loss of information at chunk boundaries. This includes LLM-based/ Agentic chunking strategy where we use an LLM to analyze the content to identify points to break logically based on standalone-ness and semantic coherence.
from langchain_openai import AzureChatOpenAI
from langchain.prompts import PromptTemplate
llm = AzureChatOpenAI(
model="gpt-4o",
api_version="2023-03-15-preview",
verbose=True,
temperature=1
)
prompt_text = """
I am providing a document below.
Please split the document into chunks that are contextually coherent and don't split where the splits distort in meaning, making sure each chunk is a complete, meaningful section. Each chunk should preserve the context without breaking important ideas across chunks. Use your understanding of the document's structure and flow to find natural breakpoints.
Ensure no chunk exceeds 1000 characters and prioritize grouping related concepts or sections together.
Do not change the document content--only split it and return the chunks as a list of strings, each one a chunk of the document.
Document:
{document}
"""
prompt_template = PromptTemplate.from_template(prompt_text)
chain = prompt_template | llm
result = chain.invoke({"document": text_data})Common Pitfalls in Chunking and How to Avoid Them
Overlapping Chunks Incorrectly
Breaking text in the middle of a sentence or paragraph can cause chunks to lose their meaning. To avoid this, overlapping methods like a sliding window are used, so that information at the edges appears in both chunks. However, too much overlap can lead to repeat information, making processing less efficient and the results less clear. So, it’s important to find the right balance for the overlap size.
Context Loss between Chunks
Traditional chunking approaches can lead to context loss by chunking some predefined metric. We can prevent any key information loss using hybrid chunking and windowed summarization or by implementing agentic chunking.
Granularity Mismatch with Retrieval Models
Granularity mismatches happen when people search for information; they often use general terms, while the documents they need may contain more specific examples. For example, a search might use the word “antipsychotic,” but the documents may mention specific drugs like “Diazepam” or brand names like “Valium.” This difference, known as granularity mismatch, is common in medical searches, especially with electronic patient records, which include detailed descriptions and analysis. A simple keyword search struggles here because the search is general, but the documents are very specific.
A hierarchical chunking approach can help retrieve the most relevant information. For example, if a user queries for “antipsychotic,” the system could retrieve general information chunks about antipsychotics but also smaller chunks about individual drugs, allowing users to dive deeper if they choose to.[6]
Latest Trends in Chunking Strategies
- Anthropic’s contextual embedding: Contextual retrieval strategy which adds chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”). This contextual chunk addition is facilitated by an LLM. To implement contextual retrieval, instructions are given to the LLM model to provide concise chunk-specific context that explains the chunk using the context of the overall document.[7]\
- ChunkRAG: A framework that improves RAG systems by evaluating and filtering retrieved information at the chunk level. This approach uses semantic chunking to split documents into meaningful sections and applies LLM-based relevance scoring to determine each chunk’s alignment with the user’s query.[8]
Conclusion
Chunking serves as a foundational process, breaking down large documents into smaller, manageable sections, allowing models to retrieve and generate relevant information more efficiently. Integrating chunking into Retrieval-Augmented Generation (RAG) is crucial for enhancing the retrieval and generation processes.
In this article, we’ve highlighted the importance of chunking and examined various strategies for its implementation, complete with code examples. Additionally, we’ve outlined a pipeline to evaluate these chunking strategies effectively.
We’ve also addressed the challenges and common pitfalls encountered in chunking, along with advanced and optimized strategies for improved performance.
References
- Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
- [2406.00456] Mix-of-Granularity: Optimize the Chunking Granularity for Retrieval-Augmented Generation
- Introducing Contextual Retrieval \ Anthropic
- [2410.19572] ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
- Context Precision - Ragas
- Faithfulness - Ragas
- Evaluating - LlamaIndex
- Information retrieval as semantic inference: a Graph Inference model applied to medical search | Discover Computing


-Feature-Image.CjBFdO7y_Z1JlSjK.webp)